
۱۵ الگوریتم یادگیری ماشین که به درد هر پروژه میخورند ( ۲۰۲۵)
941 بازدید
زمان مطالعه: 15 دقیقه

یادگیری ماشین دیگر فقط یک واژه تخصصی در کتابهای مهندسی نیست؛ حالا جزئی جدانشدنی از زندگی روزمره ما شده است. از پیشنهادهای هوشمند نتفلیکس و یوتیوب برای تماشای فیلم گرفته تا خودروهای خودران تسلا و حتی همین جستوجوهای ساده در گوگل، همه و همه به کمک الگوریتمهای یادگیری ماشین ممکن شدهاند.
با این همه کاربرد، طبیعی است که بخواهید با انواع الگوریتمهای ماشین لرنینگ بیشتر آشنا شوید و بدانید کدامیک برای پروژه شما مناسبتر است. در این مقاله محبوبترین الگوریتمهای یادگیری ماشین در سال ۲۰۲۵ را بررسی میکنیم. آمادهاید شروع کنیم؟
چند نوع الگوریتم یادگیری ماشین داریم؟
الگوریتمهای یادگیری ماشین به ۴ دسته اصلی تقسیم میشوند که هر کدام روش خاصی برای یادگیری دارند و با نوع خاصی از دادهها کار میکنند. این چهار دسته عبارتاند از:
- یادگیری نظارتشده
- یادگیری نظارتنشده
- یادگیری نیمهنظارتشده
- یادگیری تقویتی
هرکدام از این روشها در شرایط مختلف کاربرد دارند. اگر میخواهید نحوه پیادهسازی الگوریتمهای ماشین لرنینگ و هوش مصنوعی را بهصورت پروژهمحور یاد بگیرید، میتوانید در دوره آموزشی هوش مصنوعی فناپکپس شرکت کنید.، حالا بیایید بیشتر با این روشها آشنا شویم.
یادگیری نظارتشده (Supervised Learning)
این نوع ماشین لرنینگ از دادههای برچسبدار یاد میگیرد. شبیه به یک معلم که جواب درست را به شما نشان میدهد. بعد از آموزش، میتواند برای دادههای جدید پیشبینیهایی انجام دهد. مثل:
- شناسایی ایمیلهای اسپم
- پیشبینی وضعیت آبوهوا
یادگیری بدون نظارت (Unsupervised Learning)
در این روش، الگوریتم خودش بهتنهایی به دنبال الگوها یا گروهها میگردد. مشابه وقتی که بدون راهنمایی یک کمد را مرتب میکنید. این روش برای دستهبندی مشتریان یا شناسایی مشکلات در دادهها کاربرد دارد.
یادگیری نیمه نظارت شده (Semi-Supervised Learning)
در این روش، مدل از ترکیب دادههای برچسبدار و بدون برچسب استفاده میکند. مثل معلمی که به شما فقط چند سوال با پاسخ میدهد، ولی بیشتر موارد را خودتان باید حدس بزنید. این روش زمانی مفید است که جمعآوری دادههای برچسبدار هزینهبر باشد.
مثل تشخیص بیماریها با استفاده از تعداد کمی تصویر پزشکی برچسبدار و حجم زیادی از تصاویر پزشکی بدون برچسب.
یادگیری تقویتی (Reinforcement Learning)
در این مدل، الگوریتم از طریق آزمون و خطا یاد میگیرد. برای تصمیمهای درست پاداش میگیرد و برای اشتباهات تنبیه میشود، شبیه به آموزش دادن به یک حیوان خانگی با استفاده از جوایز.
مقایسهای الگوریتمهای یادگیری ماشین
الگوریتمهای یادگیری ماشین بسته به نوع یادگیری، تفاوتهای زیادی با هم دارند. در جدول زیر، میتوانید مقایسهای بین یادگیری نظارتشده، بدون نظارت، نیمهنظارتشده و یادگیری تقویتی ببینید:
| نوع الگوریتم | هدف کلی | روش یادگیری | کاربردها | مزایا | معایب |
| نظارتشده | پیشبینی جواب براساس دادههای برچسبدار | یادگیری از مثالهای ورودی با جواب مشخص | تشخیص اسپم، پیشبینی قیمت سهام، کشف تقلب | دقت بالا، قابل فهم و اجرا | نیاز به دادههای زیاد و برچسبدار، زمانبر بودن برچسبگذاری |
| نظارتنشده | پیدا کردن الگو در دادههای بدون برچسب | کشف ساختار پنهان در دادهها | دستهبندی مشتریها، کشف ناهنجاری، پیشنهاد محصول | مناسب برای دادههای خام، نیازی به برچسب نیست | تفسیر نتایج سخت است، اعتبارسنجی دشوار |
| نیمهنظارتشده | ترکیبی از یادگیری با و بدون برچسب | استفاده از تعداد کمی داده برچسبدار | شناسایی گفتار، طبقهبندی متن، تحلیل زیستی | نیاز کمتر به دادههای برچسبدار، کارآمدتر | احتمال خطا بهخاطر کم بودن برچسبها |
| تقویتی | یادگیری از تجربه برای تصمیمگیری بهتر | آزمون و خطا با بازخورد از محیط | رباتها، ماشینهای خودران، بازیهای کامپیوتری | یادگیری خودکار، سازگار با شرایط متغیر | زمانبر، نیاز به منابع محاسباتی زیاد |
با ۱۵ تا از بهترین الگوریتمهای یادگیری ماشین آشنا شوید
الگوریتمهای یادگیری ماشین انواع مختلفی دارند. در ادامه، رایجترین آنها را براساس نوع یادگیری معرفی میکنیم.
۱. رگرسیون خطی (Linear Regression) (یادگیری نظارتشده)
الگوریتم رگرسیون خطی نشان میدهد که چطور یک متغیر میتواند روی متغیر دیگر تاثیر بگذارد. در این الگوریتم، متغیر مستقل بهعنوان عامل توضیحدهنده و متغیر وابسته هدف اصلی شناخته میشود.
در واقع، این الگوریتم میخواهد بفهمد که تغییرات در یک عامل چگونه میتواند باعث تغییر در عامل دیگر شود. این الگوریتم برای پیشبینی عددهایی مثل قیمت یا مقدار، براساس رابطهای خطی بین چند متغیر استفاده میشود، مثل پیشبینی قیمت خانه، میزان فروش یا حقوق افراد.
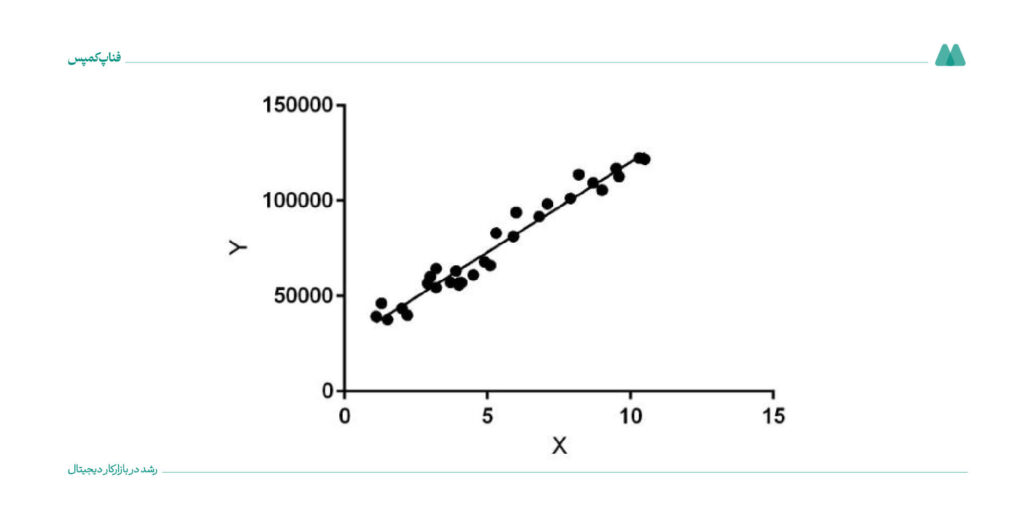
برای مثال، الگوریتم رگرسیون خطی میتواند با استفاده از اطلاعاتی مثل اندازه خانه و تعداد اتاقها، قیمت آن را پیشبینی کند.
- مزایا: ساده است، سریع یاد میگیرد و سریع پیشبینی میکند، و میشود بهراحتی فهمید که چطور ورودیها روی نتیجه اثر میگذارند.
- معایب: در مسائل پیچیده یا وقتی رابطه بین دادهها خطی نیست، خوب کار نمیکند؛ همچنین به دادههای اشتباه یا نویز حساس است.
۲. رگرسیون لجستیک (Logistic Regression) (یادگیری نظارتشده)
الگوریتم رگرسیون لجستیک برای پیشبینی مقادیر گسسته (مثل بله یا نه) استفاده میشود، درحالیکه رگرسیون خطی برای پیشبینی مقادیر پیوسته (مثل اندازه یا میزان) کاربرد دارد.
به این ترتیب، رگرسیون لجستیک بیشتر برای مسائل طبقهبندی دودویی مناسب است. این الگوریتم احتمال وقوع یک رویداد خاص را با توجه به دادههای پیشبینیکننده بررسی میکند.
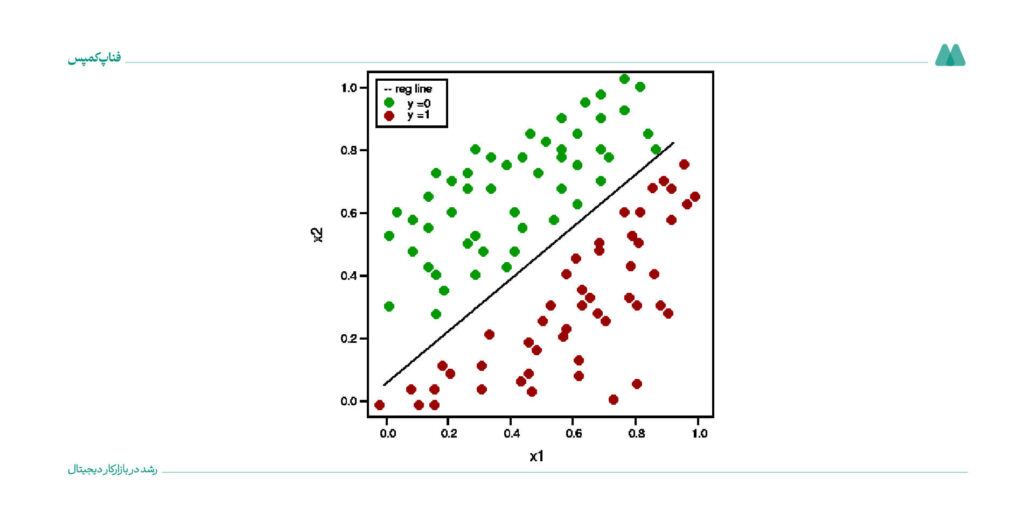
این الگوریتم برای مسائل طبقهبندی دوکلاسه مثل پیشبینی وقوع یک رویداد خاص کاربرد دارد. مثلاً، میتوانید با این الگوریتم احتمال لغو اشتراک یک مشتری را پیشبینی کنید.
- مزایا: استفاده آسان و سریع برای مسائل طبقهبندی دودویی؛ نتایج احتمال بهوضوح قابل فهم است.
- معایب: عملکرد ضعیف در مسائل پیچیده یا غیرخطی؛ مرز تصمیمگیری ممکن است بهصورت خطی باشد.
۳. درخت تصمیم (Decision Tree) (یادگیری نظارتشده)
الگوریتم درخت تصمیم یکی از روشهای ساده و کاربردی یادگیری ماشین است که میتواند هم برای دستهبندی دادهها و هم برای پیشبینی مقدارها به کار برود. این الگوریتم با یاد گرفتن چند قانون ساده از ویژگی دادهها، مدلی میسازد که به کمک آن میتوانید نتیجه نهایی یا مقدار موردنظر را پیشبینی کنید.
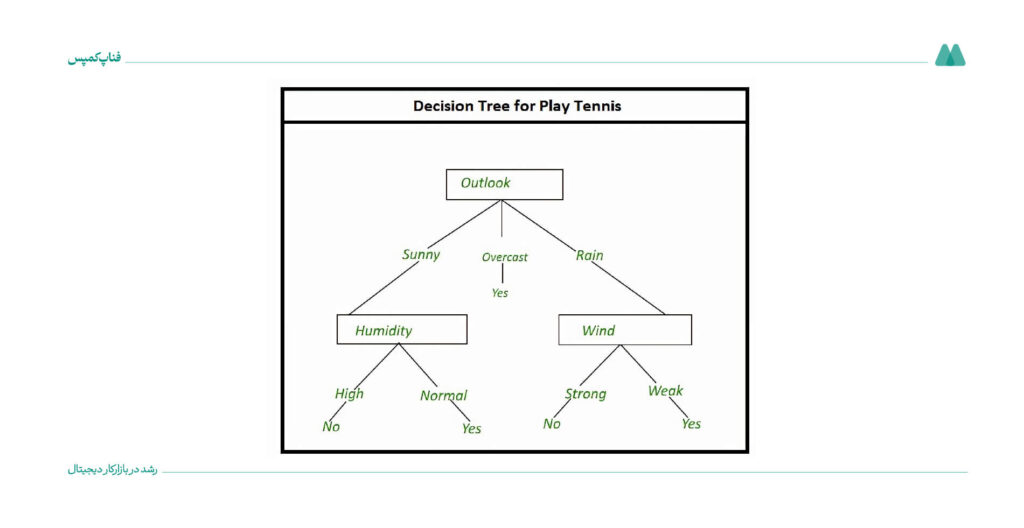
همانطور که گفتیم درخت تصمیم هم برای دستهبندی (مثلاً تشخیص اینکه یک ایمیل اسپم است یا نه) و هم برای پیشبینی عددی (مثل پیشبینی قیمت خانه) استفاده میشود. مثلاً با کمک آن میتوانید فهمید که آیا یک مشتری جدید محصولی را میخرد یا نه.
- مزایا: قابل فهم و ساده برای توضیح دادن (نتایجش شبیه جملههای «اگر… آنگاه…») است و نیاز چندانی به تمیز کردن یا آمادهسازی اولیه دادهها ندارد.
- معایب: احتمال دارد مدل بیشازحد با دادههای آموزشی سازگار شود (بیشبرازش)، در برابر تغییرات کوچک در دادهها حساس است؛ در مسائل خیلی پیچیده عملکرد خوبی ندارد.
۴. جنگل تصادفی (Random Forests) (یادگیری نظارتشده)
الگوریتم جنگل تصادفی مشکلات الگوریتم درخت تصمیم را برطرف میکند. یکی از مشکلات این است که وقتی تعداد تصمیمگیریها در یک درخت زیاد میشود، دقت آن کاهش پیدا میکند.
در الگوریتم جنگل تصادفی، چندین درخت تصمیم وجود دارد که هر کدام نتایج مختلفی را نشان میدهند. همه این درختها به یک مدل به نام CART (درختهای طبقهبندی و رگرسیون) تبدیل میشوند.
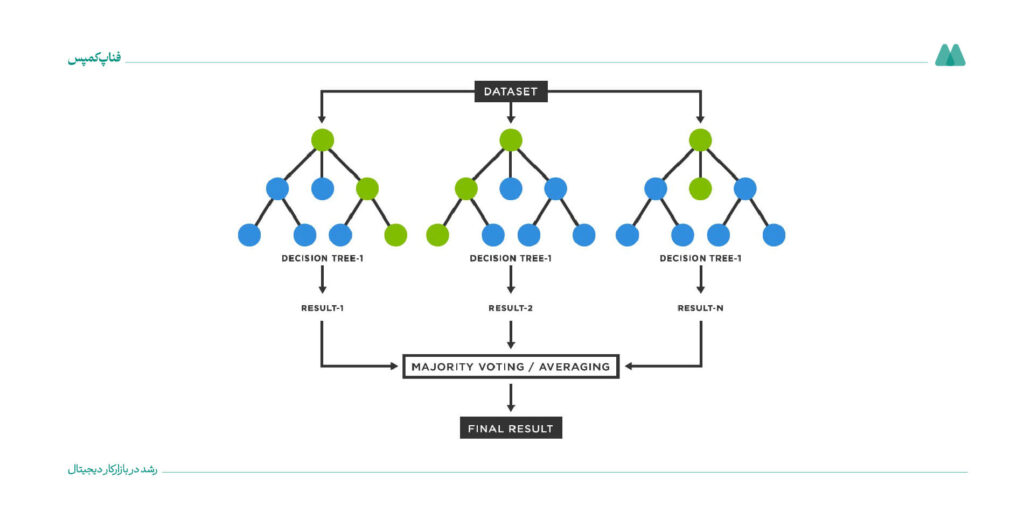
این مدل برای حل مشکلات درختهای تصمیم به کمک چندین درخت تصمیم (CART) طراحیشده است و با ترکیب نتایج چندین درخت تصمیم، دقت پیشبینی را بیشتر میکند. مثلاً در پیشبینی وامدهی، الگوریتم جنگل تصادفی میتواند خطای مدلهای تکدرختی را کاهش دهد.
- مزایا: کاهش احتمال خطای مدل (بیشبرازش) نسبت به درختهای منفرد؛ دقت بالاتر و توانایی مدلسازی روابط پیچیدهتر؛ کارایی بهتر با دادههای بزرگ و ویژگیهای زیاد.
- معایب: پیچیدگی بیشتر در محاسبات و زمان آموزش بیشتر؛ تفسیر مدل سختتر (شناسایی تاثیر ویژگیها نسبت به یک درخت منفرد مشکلتر است).
۵. ماشین بردار پشتیبان (Support Vector Machine|SVM) (نظارتشده)
الگوریتم ماشین بردار پشتیبان برای طبقهبندی یا پیشبینی استفاده میشود. در این روش، دادهها با پیداکردن یک خط خاص (Hyperplane) که دادهها را به گروههای مختلف تقسیم میکند، طبقهبندی میشوند.
این الگوریتم تلاش میکند خطی را پیدا کند که فاصله بین گروهها را بیشتر کند (که به این کار حداکثر کردن حاشیه میگویند).
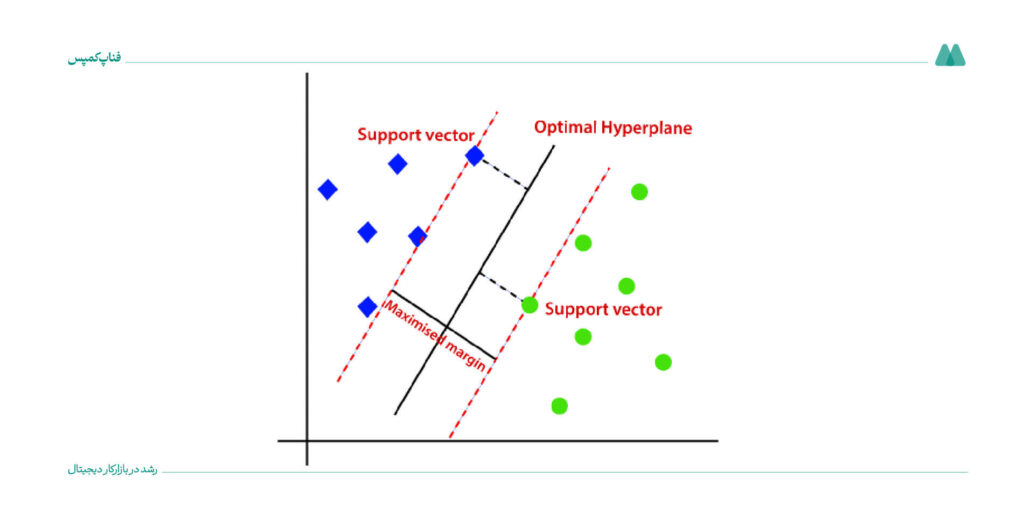
مدل SVM برای دستهبندی و پیشبینی مسائل مختلف، بهویژه دادههای پیچیده و با ابعاد زیاد استفاده میشود. این مدل تلاش میکند با انتخاب یک مرز (صفحه) که بیشترین فاصله را بین دو گروه داده ایجاد میکند، دادهها را از هم جدا کند.
- مزایا: ایجاد مرز تصمیم بهینه با حاشیه بزرگ؛ عملکرد خوب در دادههای با ابعاد زیاد.
- معایب: نیاز به محاسبات زیاد (بهخصوص وقتی تعداد نمونهها زیاد باشد)؛ نیاز به تنظیم دقیق پارامترها و متغیرهای الگوریتم؛ عملکرد ضعیف در صورت وجود نویز زیاد یا دادههای نامتعادل.
۶. نزدیکترین همسایه (K-Nearest Neighbors|KNN) (نظارتشده)
الگوریتم K-Neares یا نزدیکترین همسایه، دادهها را براساس شباهتشان به گروههای مختلف تقسیم میکند. برای پیشبینی یک نقطه داده جدید، الگوریتم به دنبال K داده مشابه در مجموعه داده میگردد و نتیجه را از میان این K نمونه استخراج میکند.
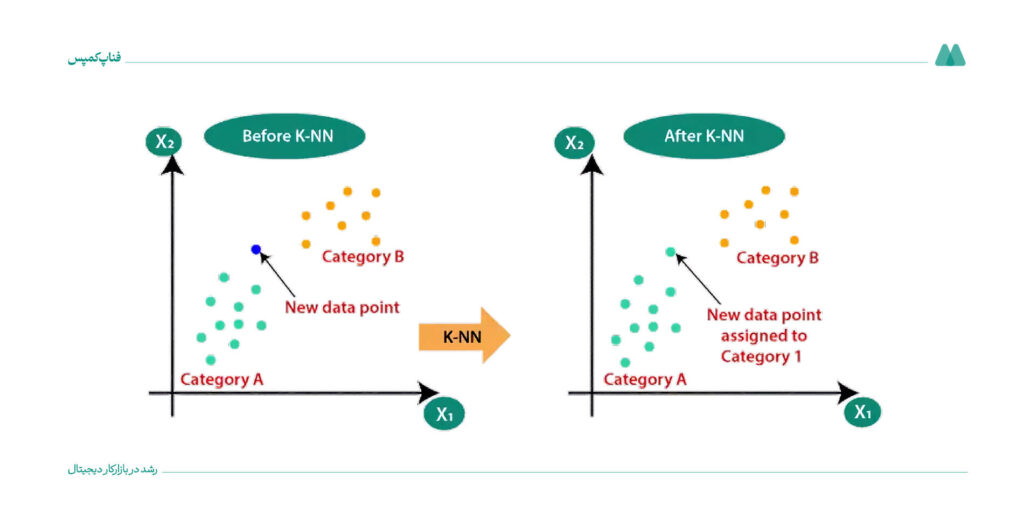
مدل KNN برای طبقهبندی و رگرسیون از مقایسه فاصله استفاده میکند. هنگام پیشبینی، این مدل نزدیکترین k نمونه از دادههای آموزشی را پیدا کرده و براساس آن تصمیم میگیرد.
مثلاً در تشخیص گونههای گیاهی، الگوریتم KNN میتواند یک گیاه جدید را براساس مشابهترین گیاهان شناختهشده دستهبندی کند.
- مزایا: یادگیری ساده (فرایند اصلی در پیشبینی انجام میشود و نیازی به آموزش پیچیده ندارد)؛ نیاز کم به فرضیات اولیه درباره دادهها دارد.
- معایب: حافظهبر و کند برای دادههای بزرگ (چون باید کل دادهها را جستجو کند)؛ حساس به ابعاد بالا (نیاز به معیار مناسب فاصله و کاهش ابعاد)؛ انتخاب مقدار مناسب k چالشبرانگیز است.
۷. بیز ساده (Naive Bayes) (نظارتشده)
الگوریتم طبقهبندی نایو بیز (Naive Bayes Classifier) روش یادگیری ماشین است که برای تقسیمبندی دادهها به دستههای مختلف استفاده میشود. این الگوریتم براساس نظریه بیز عمل کرده و احتمال تعلق یک داده به هر دسته را با توجه به ویژگیهای آن محاسبه میکند.
برای درک بهتر، فرض کنید میخواهید ایمیلهای دریافتی در جیمیل خود را به دو دسته «هرزنامه» و «غیرهرزنامه» تقسیم کنید تا صندوق ورودی شما خلوتتر شود. بیز ساده این کار را برایتان انجام میدهد.
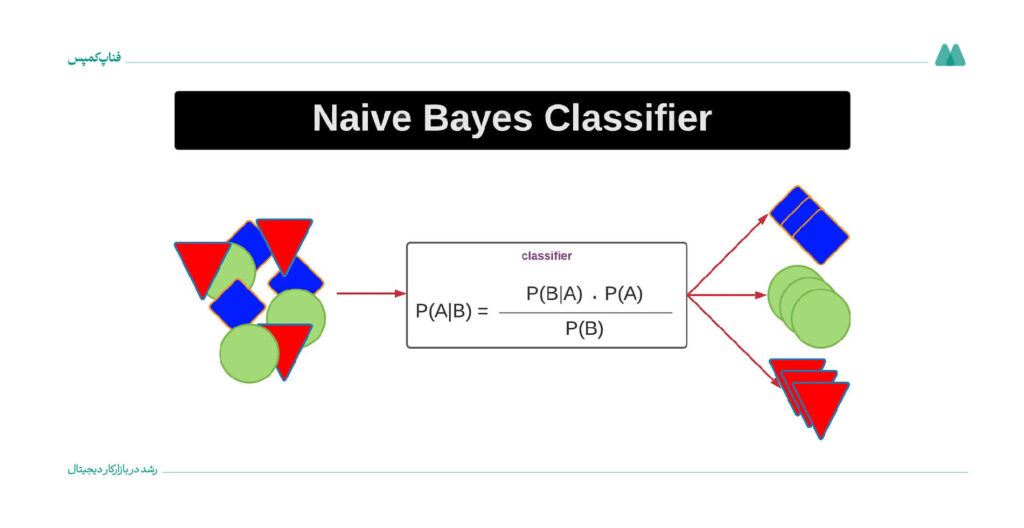
این روش برای دستهبندی سریع براساس احتمال استفاده میشود. برای مثال، در تشخیص ایمیلهای اسپم، الگوریتم Naive Bayes کلماتی مثل «رایگان» یا «برنده» را بررسی و با استفاده از فرمول بیز احتمال اسپم بودن ایمیل را محاسبه میکند.
- مزایا: آموزش و پیشبینی سریع؛ مناسب برای دادههای بزرگ؛ عملکرد خوب در دستهبندی متنی.
- معایب: فرض سادهای درباره استقلال ویژگیها دارد که همیشه درست نیست؛ عملکرد ضعیف در مسائل پیچیده یا وقتی ویژگیها به هم وابسته هستند.
۸. شبکه عصبی مصنوعی (Artificial Neural Network|ANN) (نظارتشده)
شبکه عصبی مصنوعی مدل کامپیوتری است که از روی مغز انسان الهام گرفتهشده است. از این مدل برای انجام کارهایی مثل دستهبندی اطلاعات یا پیشبینی عددی استفاده میشود.
این شبکه از واحدهایی به نام نورون ساختهشده که در چند لایه به هم وصل هستند:
- دادهها وارد شبکه میشوند.
- نورونها دادهها را پردازش میکنند.
- در نهایت خروجی بهصورت دستهبندی یا پیشبینی تولید میشود.
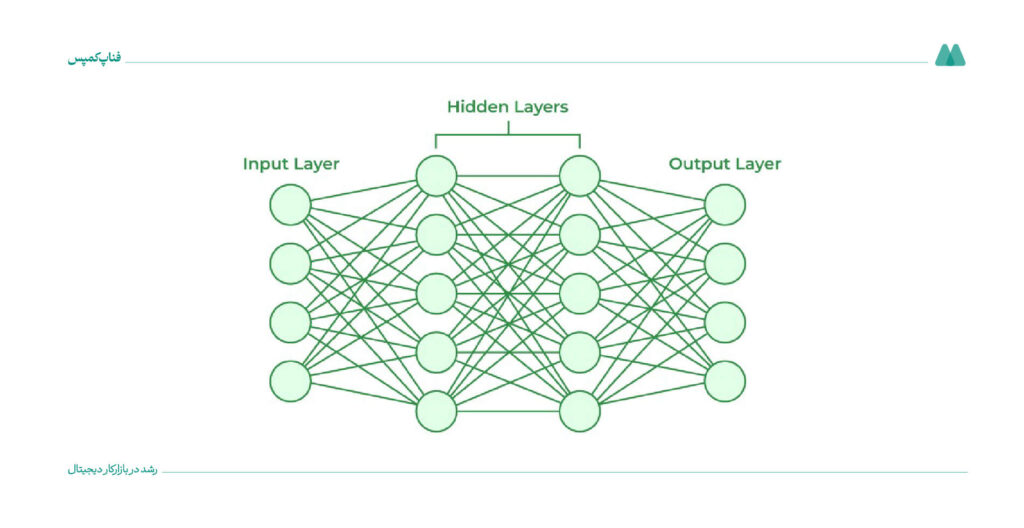
برای تقریب توابع پیچیده غیرخطی، این شبکهها کاربردهای زیادی دارند، مثل:
- تشخیص الگو
- شناسایی دستخط
- پیشبینی سریهای زمانی
ساختار این شبکهها از لایههای مختلف تشکیل شده و با روش پسانتشار خطا آموزش میبینند.
- مزایا: توانایی مدلسازی پیچیدگیهای غیرخطی عالی است؛ بهراحتی میتوان آنها را به دادههای مختلف مثل تصویر، صدا و متن تطبیق داد و عملکرد خوبی در دادههای حجیم دارند.
- معایب: نیاز به دادههای آموزشی زیاد و منابع محاسباتی بالا دارند؛ اگر ساختار شبکه بزرگ باشد و داده کم باشد، احتمال بیشبرازش وجود دارد؛ آموزش زمانبر است و تنظیم پارامترها نیاز به دقت زیادی دارد.
۹. خوشهبندی کا-میانگین (K-Means Clustering) (نظارتنشده)
الگوریتم K-Means روش محبوب یادگیری ماشین است که برای تقسیم دادهها به گروههای مختلف براساس شباهتهای آنها استفاده میشود.
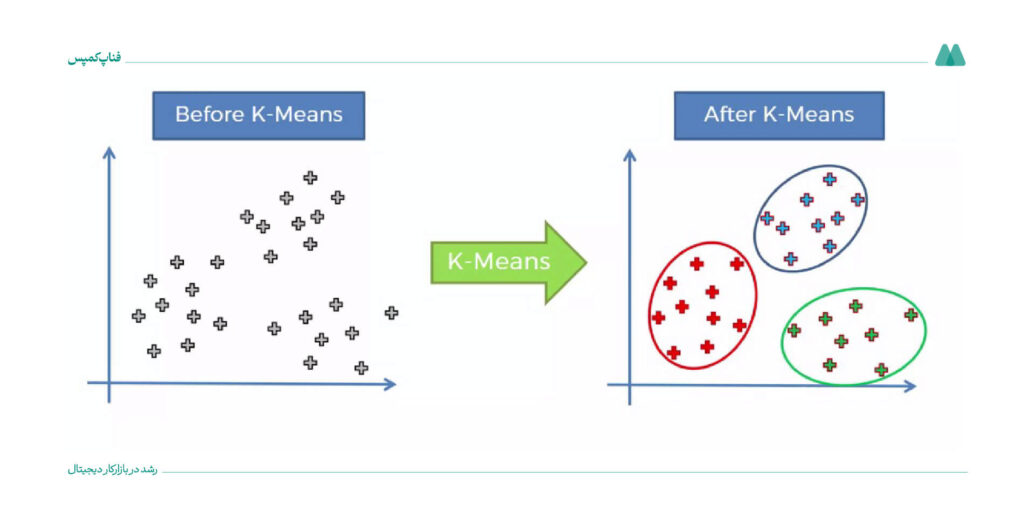
این روش کاربرد زیادی در تحلیل بازار (برای تقسیمبندی مشتریان)، پردازش تصویر (برای خوشهبندی پیکسلها) و تحلیل شبکههای اجتماعی دارد تا الگوهای پنهان در دادهها را پیدا کند.
- مزایا: الگوریتم ساده و سریع است؛ برای خوشهبندیهای کروی مناسب است؛ میتواند دادههای زیاد را پردازش کند.
- معایب: باید تعداد خوشهها (K) را از قبل تعیین کرد؛ حساس به انتخاب اولیه خوشهها است؛ فقط خوشههای با شکل کروی را شناسایی میکند و در خوشههای با اشکال یا تراکمهای مختلف عملکرد ضعیفی دارد.
۱۰. تجزیه مولفههای اصلی (Principal Component Analysis|PCA) (نظارتنشده)
تجزیهوتحلیل مولفههای اصلی روشی برای کاهش ابعاد دادهها است. این روش کمک میکند دادههایی که ویژگیهای زیادی دارند، به شکل سادهتری تبدیل شوند، طوریکه بخش زیادی از اطلاعات اصلی آنها حفظ شود. در واقع، PCA مولفههایی را پیدا میکند که بیشترین اطلاعات را در دل خود دارند.
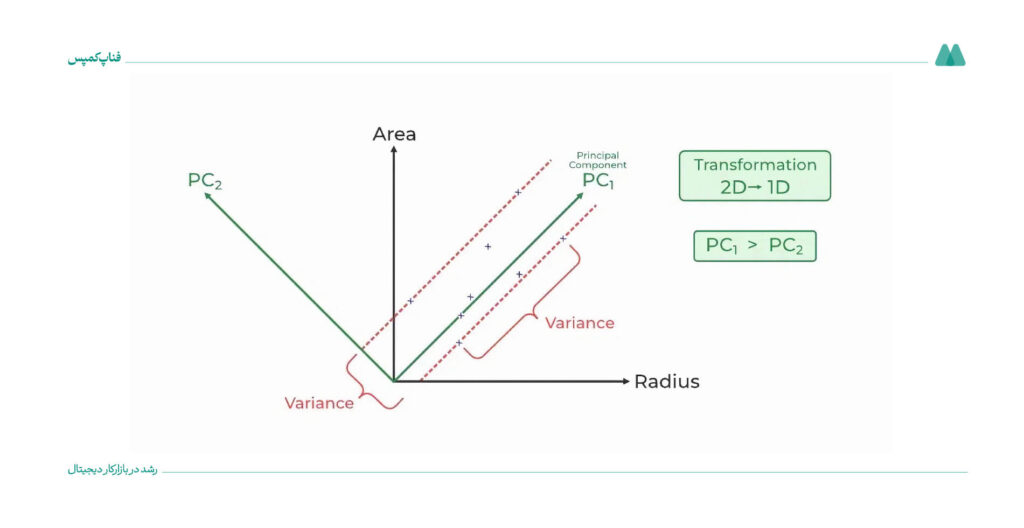
این الگوریتم برای کاهش ابعاد دادهها کاربرد دارد، بدون اینکه اطلاعات مهم (واریانس) زیادی از بین برود. در واقع PCA ویژگیهای اصلی و مهم دادهها را شناسایی میکند و دادهها را در ابعاد کمتر (مثلاً ۲ یا ۳ بعد) نمایش میدهد. از این مدل برای آمادهسازی دادهها قبل از اجرای الگوریتمهای دیگر یا برای نمایش تصویری دادهها استفاده میشود.
- مزایا: روش ساده و کاربردی برای کاهش ابعاد، حذف نویز و روابط تصادفی بین داده است؛ برای دادههای با ابعاد بسیار بالا، پیشپردازش خوبی محسوب میشود.
- معایب: درک سخت معنای هر مولفه (چون ترکیبی از چند ویژگی مختلف است). فقط روابط خطی را بررسی میکند و ممکن است نتواند روابط غیرخطی مهم را تشخیص دهد.
۱۱. اپریوری (Apriori) (نظارتنشده)
الگوریتم اپریوری از قاعده IF_THEN برای ایجاد قوانین انجمنی استفاده میکند. یعنی اگر رویداد A اتفاق بیفتد، احتمال وقوع رویداد B هم وجود دارد. این الگوریتم برای پیدا کردن مجموعههای اقلامی که معمولاً با هم خریداری میشوند و ایجاد قوانین انجمنی در پایگاههای داده تراکنشی کاربرد دارد.
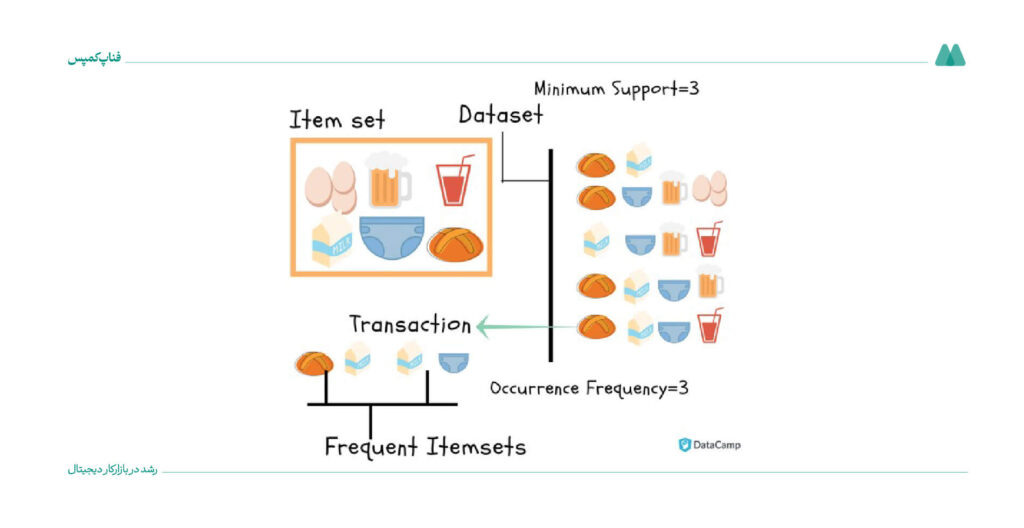
الگوریتم اپریوری برای شناسایی الگوهای تکراری یا روابط همزمان میان آیتمها در پایگاه دادههای بزرگ تراکنشها استفاده میشود.
یکی از کاربردهای اصلی آن تحلیل سبد خرید مشتریان است؛ مثلاً اگر مشتریان نان و پنیر را همزمان خریداری کنند، الگوریتم اپریوری این رابطه را شناسایی میکند. همچنین در زمینههای پزشکی، بیوانفورماتیک و تشخیص تقلب هم کاربرد دارد.
- مزایا: پیادهسازی ساده، کمک به تحلیل رفتار مشتری، امکان تنظیم آستانهها، کاربرد در انواع دادهها.
- معایب: کارایی پایین در دادههای بزرگ، نیاز به اسکن مکرر پایگاه داده، مناسب فقط برای دادههای گسسته، احتمال تولید قوانین بیمعنی.
۱۲. آدابوست (AdaBoost|Adaptive Boosting) (نظارتشده)
الگوریتم آدابوست روشی قدرتمند در یادگیری ماشین است که چندین طبقهبند ضعیف را با هم ترکیب میکند تا یک طبقهبند قویتر بسازد. این روش، وزن نمونههای اشتباه طبقهبندیشده را تغییر میدهد تا مدل بیشتر روی دادههای سختتر تمرکز کند.
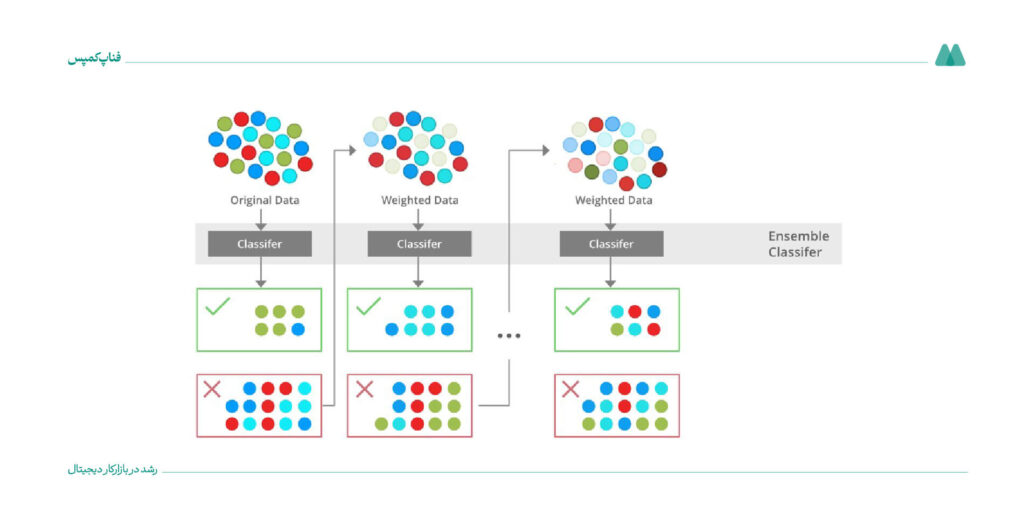
این روش با ترکیب چند مدل ساده مثل درخت تصمیمگیری کوچک، دقت مدلهای طبقهبندی مثل تشخیص اسپم را بیشتر میکند. به این مدلهای ساده «یادگیرنده ضعیف» گفته میشود.
- مزایا: روی نمونههایی که مدل بهدرستی پیشبینی نکرده تمرکز کرده و سعی میکند خطاها را کم کند. میتواند اشتباهات مدلهای ضعیف را جبران کند و از یک درخت تصمیم تنها، دقت بیشتری دارد.
- معایب: نسبت به دادههای اشتباه یا نمونههای پرت حساس است و ممکن است روی آنها دچار بیشبرازش شود. برای اینکه خوب کار کند، نیاز به دادههای دقیق و درست دارد. همچنین تنظیم پارامترهای آن سختتر از مدلهای سادهتر است.
۱۳. شبکه عصبی حافظه طولانیمدت و کوتاهمدت (LSTM) (نظارتشده)
شبکههای حافظه طولانیمدت و کوتاهمدت (Long Short-Term Memory Networks) نوعی از شبکههای عصبی هستند که بهطور خاص برای یادگیری از دنبالههای داده طراحی شدهاند.

این شبکهها بهگونهای ساخته شدهاند که میتوانند اطلاعات مهم را در حافظه نگه دارند و به خوبی از آنها استفاده کنند. این ویژگی باعث میشود مدلهای LSTM گزینهای عالی برای کارهایی مثل پیشبینی دادههای زمانی، پردازش زبان طبیعی و تشخیص گفتار باشند.
- مزایا: مناسب برای دادههای دنبالهدار و سریهای زمانی با توانایی حفظ وابستگیهای بلندمدت
- معایب: آموزش کندتر نسبت به مدلهای سادهتر و نیاز به منابع محاسباتی بیشتر
۱۴. یادگیری کیو (Q-Learning) (تقویتی)
این الگوریتم یکی از روشهای یادگیری تقویتی است که به دنبال پیدا کردن بهترین اقدام در هر وضعیت برای بهرهمندی از بیشترین پاداش است. از این الگوریتم در آموزش هوش مصنوعی برای بازیها و رباتها استفاده میشود.
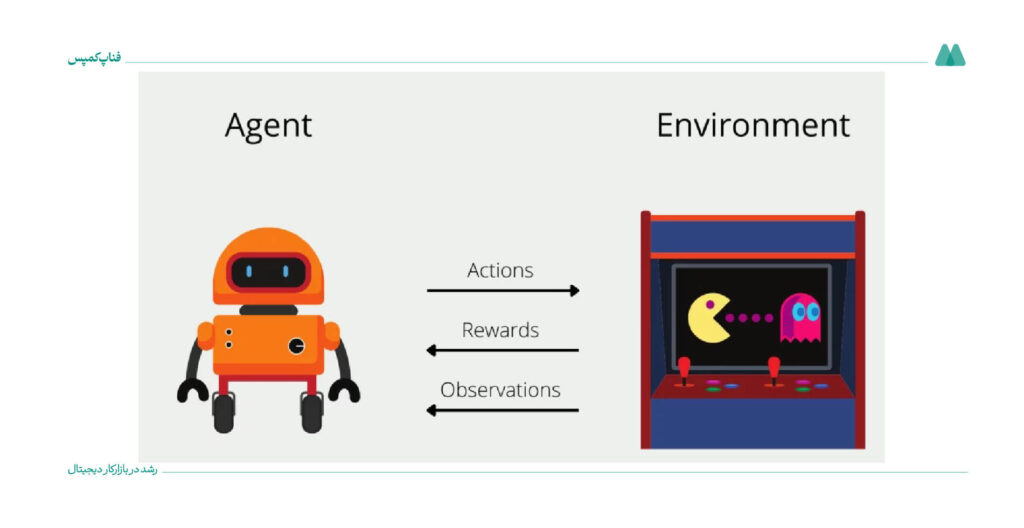
برای مثال، در سال ۲۰۱۶، آلفاگو با شکستدادن قهرمان جهان در بازی پیچیده Go همه را شگفتزده کرد. این دستاورد به لطف استفاده از Q-Learning در سیستم یادگیری تقویتی خود بود که به آن اجازه داد تا با بازی کردن با خودش، بهترین استراتژیها را بیاموزد و در بازیای که همیشه به عنوان چالشی بزرگ برای هوش مصنوعی شناخته میشد، پیروز شود.
- مزایا: این روش مستقل از شرایط محیطی است و برای یادگیری بهینه در شرایط ناشناخته عالی است. همچنین، از فضای حالت گسسته هم پشتیبانی میکند.
- معایب: در فضاهای حالت بزرگ، یادگیری به آرامی پیش میرود و نیاز به اکتشاف بیشتر دارد. همچنین، برای ذخیرهسازی جدول Q به حافظه زیادی نیاز است.
۱۵. شبکههای عصبی Q عمیق (Deep Q-Networks| DQN) (تقویتی)
الگوریتم DQN ترکیبی از یادگیری Q و شبکههای عصبی عمیق است که به مدیریت فضاهای پیچیده و بزرگ کمک میکند. این الگوریتم در زمینههایی مثل آموزش سیستمها برای بازیهای ویدیویی و کنترل رباتها کاربرد زیادی دارد.
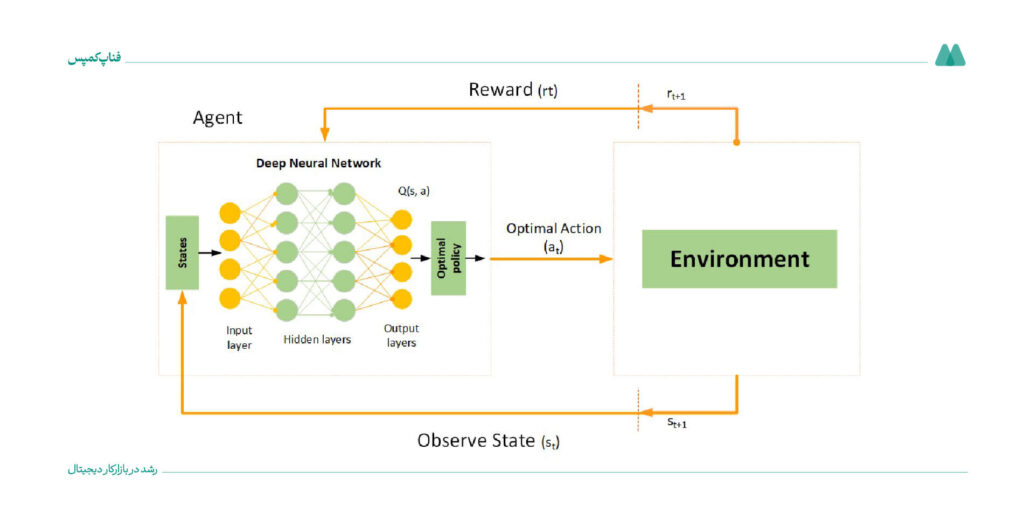
- مزایا: میتواند سیاستهای پیچیده را یاد بگیرد، چون از ترکیب Q-learning و شبکههای عصبی عمیق استفاده میکند.
- معایب: فرایند آموزش آن ممکن است ناپایدار باشد و نیاز به تنظیم دقیق پارامترها دارد.
ساخت ماشینهای هوشمند با الگوریتمهای ماشین لرنینگ، سادهتر از همیشه
یادگیری ماشین شامل روشها و الگوریتمهای مختلفی است و انتخاب الگوریتم مناسب بستگی به مسئله و نوع دادهها دارد.
هر الگوریتم مزایا و معایب خود را دارد؛ مثلا درخت تصمیم ساده است ولی ممکن است دقیق نباشد، جنگل تصادفی دقت بیشتری دارد ولی پیچیدهتر است و شبکههای عصبی نیاز به دادههای زیاد دارند. بنابراین، باید براساس نوع دادهها و هدف مسئله باید الگوریتم مناسب را انتخاب کنید.
در این مطلب بهترین الگوریتمهای ماشین لرنینگ را معرفی کردیم. به نظر شما استفاده از کدام مورد میتواند برای مسائل مختلف بهینهتر باشد؟
سوالات متداول شما درباره الگوریتمهای یادگیری ماشین
تنوع الگوریتمهای ماشین لرنینگ باعث میشود انتخاب الگوریتم مناسب سخت باشد. ممکن است سوالات زیادی برایتان پیش بیاید؛ در ادامه به چند سوال رایج در این زمینه پاسخ میدهیم:





